

Data Tool Kit - Machine Learning Handbook
As the quantity and diversity of the data we collect and manage increases, we need to continue to develop analytical methods that allow us to leverage data to inform our programs and management. Machine learning methods are becoming mainstream and powerful tools for analysis and predictive modeling. As datasets grow within and outside of the Water Boards, it is becoming more feasible to develop and utilize these tools ourselves. This Handbook is a living resource that will be updated as our data sets and machine learning needs evolve.
Machine Learning
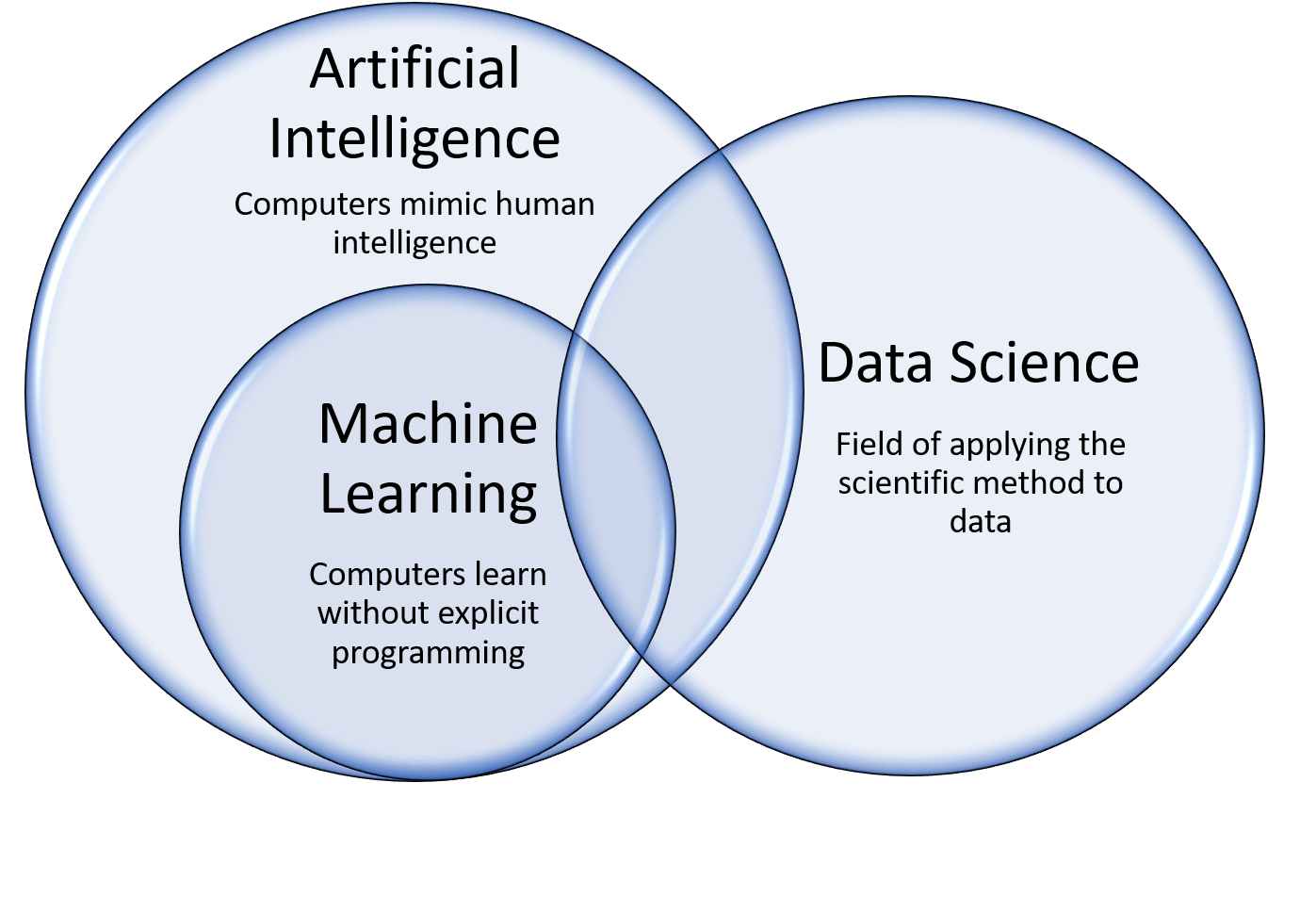
Machine learning is a subfield of data science and artificial intelligence (AI), and has a foundation of statistics and mathematical optimization. Modern AI has its origins in the 1950s from theorists and the first computer scientists like Alan Turing. Modern AI is a broad field that includes any technique that enables computers to emulate cognitive functions that humans associate with human intelligence, such as learning, logic, and problem solving. Machine learning is a subfield of AI that focuses on giving “computers the capability to learn without being explicitly programmed” (Arthur Samuel, 1959). Specifically, machine learning utilizes algorithms to automate analysis, model building, and predictions.
There are numerous and constantly evolving applications of machine learning. Here we cover a few applications of machine learning we see as being valuable to the Water Boards and outline how Water Boards staff can utilize and implement such methods in their work.
The language used in machine learning is slightly different than what many may be used to. We have mapped some key terms between the statistical and machine learning fields:
| Statistics | Machine Learning |
|---|---|
| Dependent variable Response | Target, label |
| Observation | Instance |
| Variable | Feature, attribute |
| Parameters | Weights |
| Fitting | Learning |
Supervised Learning
In supervised learning, we are tasked with finding patterns from a dataset where each observation has a label. In other words, we know what the correct input-output pairs are when we are building (training) the model. Supervised learning methods can be further classified as either regression or classification. Regression methods have a continuous prediction (i.e. some value) whereas classification methods have a categorical prediction (i.e. some category).
Unsupervised Learning
In unsupervised learning, we are tasked with finding patterns when we don’t know what the “right answers” or labels for the outputs should be.
Reinforcement Learning
In reinforcement learning, the algorithm makes decisions on what actions to take based on the environment to maximize a reward. Reinforcement learning’s focus is finding a balance between the exploration of uncharted knowledge (e.g. unsupervised learning) and the exploitation of current knowledge (e.g. supervised learning).
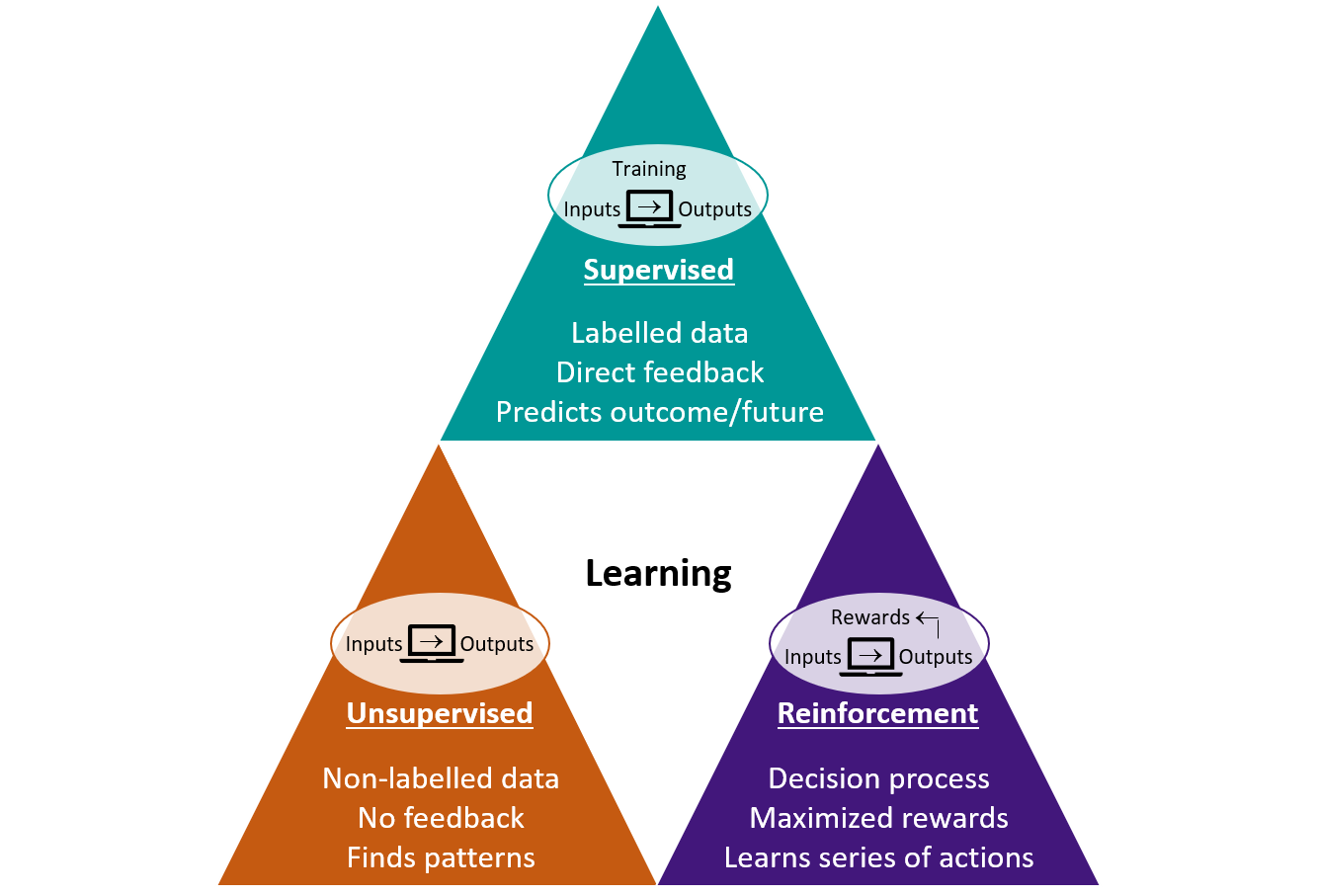
There are many different methods one could employ in a machine learning project. Click on the guide below to figure out what method would be best given your data and problem.

Applications of Machine Learning
The methods you choose will depend on the question you are asking and the type and amount of data you have. In general, the more data you have, the better off your project will be. Additionally, it is usually best to start with a simple modeling method as they provide a good baseline and often outperform complicated methods.
Predictive Modeling
Here, predictive modeling (also known as predictive analytics) techniques use tabular datasets as inputs and use statistical algorithms to predict outcomes. The most widely used predictive model algorithms include:
- Regression: linear, logistic or some other generalized linear model (GLM).
- Decision trees: these can be for regression or classification; think Random Forest
- Clustering algorithms: these methods are a form of unsupervised learning that organize your data into groups by similarity; think K-means clustering
- Naïve Bayes: this classifier allows us to predict a class or category based on a given set of features, using probabilities
- Time series: these algorithms incorporate time as a variable in the modeling process, and are often used for forecasting or predicting values in the future
After your project objectives and questions are defined (see "Data Management Handbook", Plan and Prepare section for guidance), and your data are collected and cleaned (see "Data Management Handbook", Collect and Process section for guidance), you can begin predictive modeling by following the steps below.
- Select an algorithm appropriate for your question and data.
- Select the software you would like to use (commonly used options include R/RStudio or Python; see the "Business Intelligence Handbook" for more details)
- Download software as needed
- Write code for selected algorithm (revise, as needed)
- Run code
- Export results
- Write up and report out results.
Computer Vision
Computer vision techniques gain understanding from digital imagery or videos, essentially transforming said imagery into data that can be analyzed and used to develop models and predictions. There are five main computer vision techniques:
- Image Classification: classify items within an image
- Object Detection: detect whether an object is in an image
- Object Tracking: track an object in a set of images
- Semantic Segmentation: divide an entire image into pixel groupings and label each grouping
- Instance Segmentation: classify pixel groupings within and image and identify their boundaries, differences, and relations to one another
The Water Board has utilized computer vision techniques to:
- Identify and quantify the amount of trash in West Sacramento
- Automate the identification of cannabis related agriculture, objects, and structures in geo-referenced imagery. See the Online Cannabis Compliance Gage Mapping Tool and Cannabis Priority Watersheds pages for more cannabis related information.
